Rafty -- DVD Backups using Systemd, Docker, Rabbitmq, and go
02 Apr 2015
Rafty is a scalable, fully-automated system for backing up DVD collections.
Rafty stands for Ripper and Friggin’ Transcoder, Y‘all.
Disclaimer: this is a backup solution only. Don’t pirate stuff.
Background
I recently decided it was time to make some more progress in my efforts to fully backup my DVD collection. After all, that was one of the main reasons I built a NAS a few years ago (which I recently upgraded to 8TB of storage!).
I’ve scripted the dd -> handbrake process a few times in the past, but
this time I decided to do something a little more flexible. A few of my
main requirements were:
-
User intervention shall only be required for the physical insertion and removal of discs. (And I’d like to phase that out someday as well :). Need to build a robot…)
-
The system shall be capable of scaling out arbitrarily so that idle machines I have laying around can be added to the pool to help the cause.
This also seemed like the perfect opportunity for me to use a few pieces of technology that I’ve used in the past but haven’t been able to really get my hands dirty with. Specifically:
Architecture
In its simplest configuration (a single host doing all the work), the Rafty architecture looks like this:
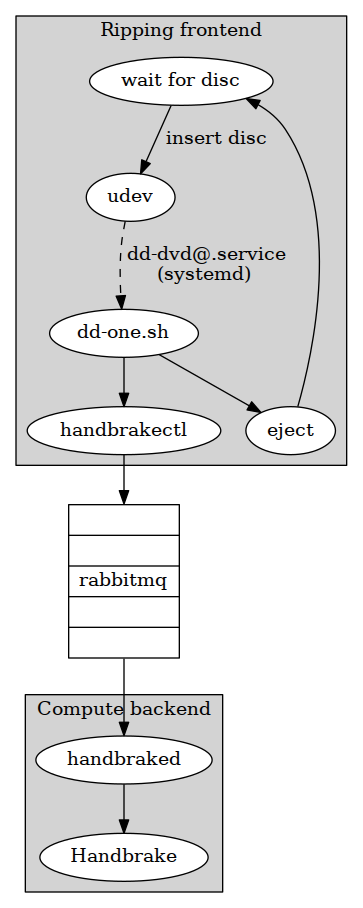 (
(Let’s walk through that diagram:
-
udevlistens for a DVD to be inserted and starts a “oneshot”systemdservice. -
The
systemdservice launches a script that usesddto copy the disc to the local hard drive. We couldn’t start ourddscript directly from ourudevrule because ofudev’s event timeout. Plus we get built-in logging and monitoring fromsystemd. -
The script ejects the disc and uses
handbrakectl(a program written ingo) to submit a job to thehandbrakeddaemon (another program written ingo) through arabbitmqnamed queue. This step might seem pointless right now but we need the queue there for when we start scaling out (below). -
handbrakedreads our job off of the queue and invokes Handbrake for transcoding. The output is saved to the appropriate directory (an 8TBbtrfsRAID-1 volume) where it is immediately available to media consumers on my home network.
This is probably overkill if you’re just just using one machine to do everything but a few fairly interesting properties fall out of this architecture:
-
Optical disc drives can be utilized at full capacity. We don’t have to wait for the transcode phase to finish before starting another copy job.
-
Optical disc drives can be added arbitrarily. Thanks to
udevandsystemdenvironment variables, there’s no hard-coding of device paths. -
Additional “ripping frontends” can be added arbitrarily. These can be local (using
handbrakectlto submit jobs for existing isos, for example), or (more interestingly) remote machines. This lets us scale out our disc copying work (IO-intensive). -
Additional “transcoding backends” can be added arbitrarily by leveraging
rabbitmq’s round-robin dispatch across consumers. These can be local or remote. All you’d need to do to spin up another remote compute node is runhandbrakedon the remote machine.rabbitmqwill take care of the rest. This lets us scale out our transcoding work (CPU-intensive).
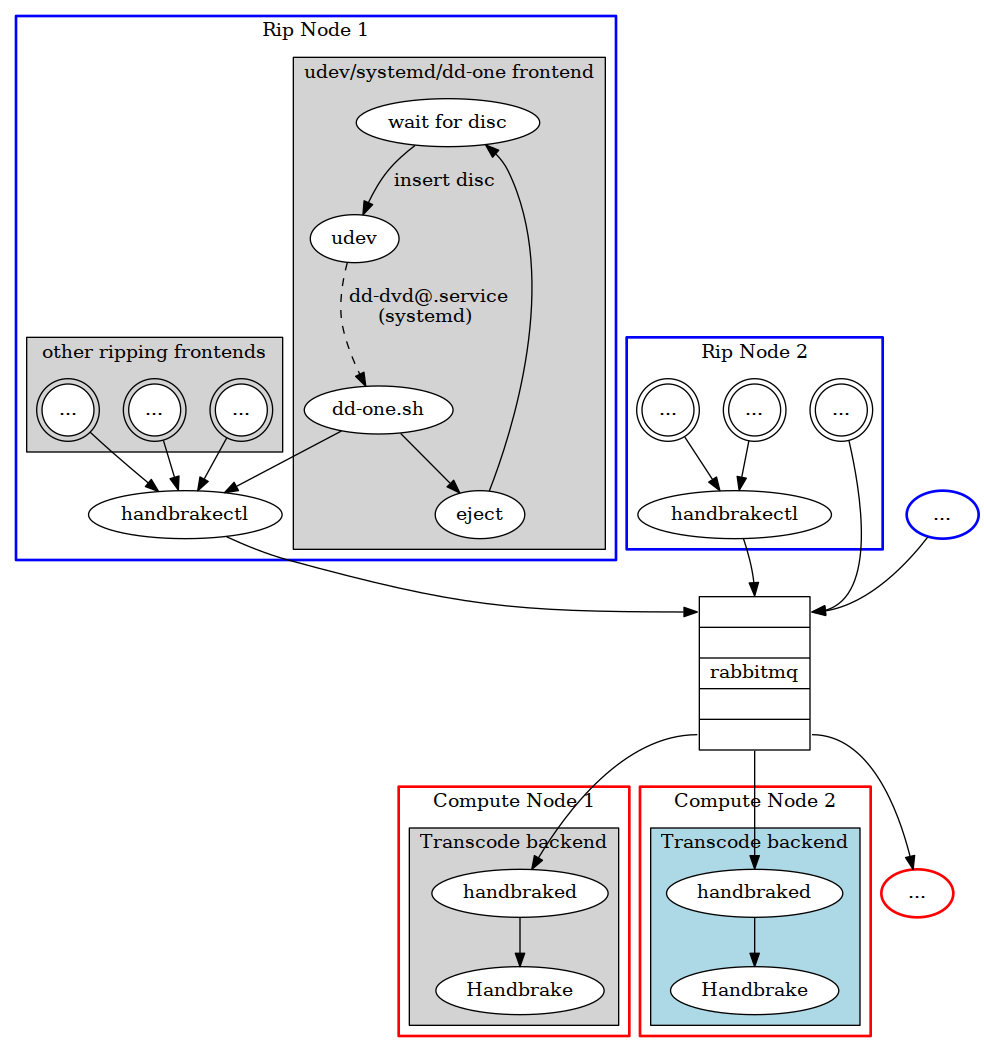
So with minimal code modifications (I’m actually hard-coding localhost in
handbrakectl and handbraked as the rabbitmq host), the system could
scale out to look like this:
 (full size)
(dot source)
(full size)
(dot source)
Those blue and red nodes can scale out virtually without limit. The only
bottleneck here would be rabbitmq message throughput, and these messages
are tiny. The bigger problem for me is the fact that I only have one
machine with a single optical disc drive to dedicate to this :).
Gratuitous over-engineering aside, this project was a lot of fun and helped me learn more about some new and interesting technologies. Hope you enjoyed it!
Source
If you want to run this behemoth at your house, head on over to the official Rafty GitHub page.
udevrule: 98-dd-one-from-udev.rulessystemdoneshot service: dd-dvd@.servicedd-one.sh: dd-one.shdd-one.conf: dd-one.confhandbrakectl.go: handbrakectl.gohandbraked.go: handbraked.go
Links
Projects
Work
- Co-Founder & CEO of Directangular, LLC.
- Previously: Linux Kernel development at Qualcomm, and embedded software at L3. You can view my upstreamed Linux kernel patches here.
- Wild blue yonder: Creating and contributing to a variety of Open Source projects. See my GitHub profile.
 Subscribe with Atom
Subscribe with Atom